
Project introduction
In this project, the goal is to do multilabel classification. A piece of news can be related to only one topic or several. The task is training a model to classify relevant themes of news. Therefore, this is also a multilabel classification problem.
I did the work of data exploring, cleaning and turning them into batches. Then I used RoBERTa and distilled BERT to tackle the task, the latter of which is lighter but has a similar performance as original model. I also compared two models and validate them on development dataset.
Text extraction & data exploration
The content of news as well as its label is embedded in xml files. So after downloading the file, the first thing we should do is extracting useful information from files.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def read_file(file_path):
file=etree.parse('./%s'%file_path)# replace it with file_path
return file.getroot()
def extract_text(file_path):
root=read_file(file_path)
file_id=root.xpath("/newsitem/@itemid")[0]
data[file_id]={}
if root.xpath("//headline/text()")!=[]:
data[file_id]["HEADLINE"]=root.xpath("//headline/text()")[0].capitalize()
else:
data[file_id]["HEADLINE"]=''
data[file_id]["TEXT"]=txt_clean(' '.join(root.xpath("//text/p/text()")))
# data[file_id]["TEXT"]=' '.join(root.xpath("//text/p/text()")).strip()
data[file_id]["LABEL"]=root.xpath("//codes[@class='bip:topics:1.0']/code/@code")
for directory in filedir:
print("%s directory completed"%directory)
for file in os.listdir('../src-data/%s'%directory):
extract_text('../src-data/%s/%s'%(directory,file))
I use lxml.etree parsing the format and xpath syntax to obtain contents and labels. Then do some data explorations. I sort of want to see how different labels are distributed; if they are unevenly labeled? What’s the most frequent label in thousands of texts.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
df_lb=pd.DataFrame(code_label)
df_lb.to_csv("../data_files/label-codes.csv")
array_label = df["label"].apply(lambda x: np.array(x))
# this corresponds to the 3rd figure in report, 10 most frequent labels
topN = 10
freq_index = (np.argsort(sum(array_label))[::-1][:topN],np.argsort(sum(array_label))[::-1][-topN:])
mostfreq_classes = [code_label["code"][i] for i in freq_index[0]]
leastfreq_classes = [code_label["code"][i] for i in freq_index[1]]
most_frequency = sorted(sum(array_label),reverse=True)[:topN]
least_frequency = sorted(sum(array_label),reverse=True)[-topN:]
most_label=pd.DataFrame({"most_classes":mostfreq_classes,"frequency":most_frequency})
least_label=pd.DataFrame({"least_classes":leastfreq_classes,"frequencies":least_frequency})
label_data=pd.concat([most_label,least_label],axis=1)
The frequency of labels turns out to be pretty imbalanced. Take a look at the following picture, we can see the most frequent label CCAT.
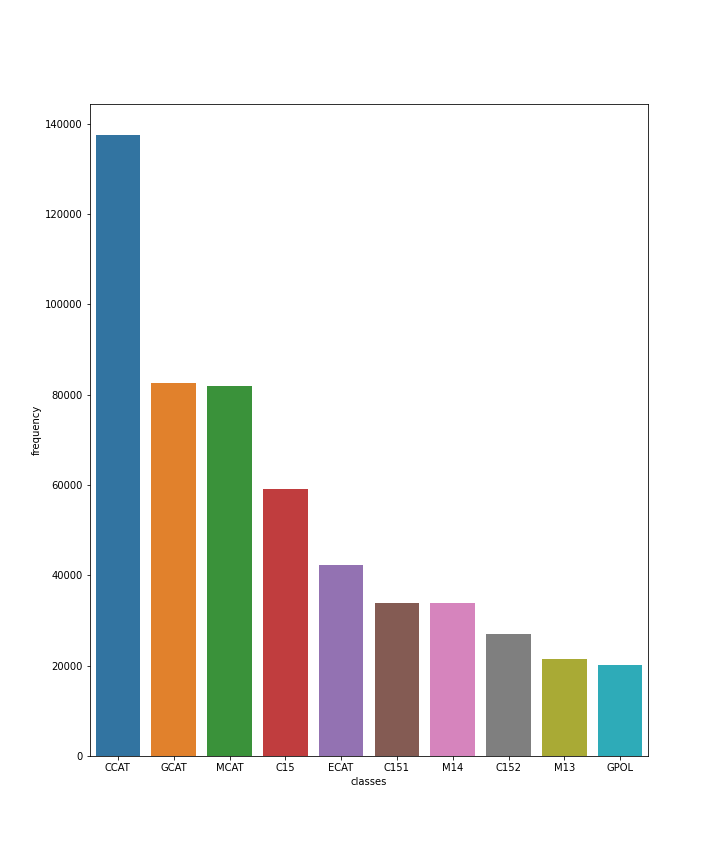 And if we compare the top 10 most frequent labels and 10 least frequent ones, we see there is a really large gap. So this issue could lead the model to focus more on the frequent labels instead of rare tags.
And if we compare the top 10 most frequent labels and 10 least frequent ones, we see there is a really large gap. So this issue could lead the model to focus more on the frequent labels instead of rare tags.
Another discovery is that there are totally 126 different topics. Thereby the output of the neural model should be a vector including 126 elements standing for possiblities of the topics.
How about the texts? The maximum tokens BERT model can deal with as input is 512. So if text length exceeds the limitation too much, only part of contents will be processed.
 OK, we can see majorities are within 512 tokens.
OK, we can see majorities are within 512 tokens.
Data transformation and preparation
- Since the label is in format of string. For example, [‘CCAT’, C15’’] or [‘M14’]. In order to convert the labels into a format we can use for calculating loss, it should be in one-hot encoding.
1
2
3
4
5
6
7
8
9
10
#transforming labels into one-hot encoding
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer(classes=df_lb["code"])
def labels2binaries(label,model=mlb):
return model.fit_transform(label)
onehot_label = labels2binaries(df["LABEL"])
df["label"] = onehot_label.tolist()
df[['text','label']].to_csv("../data_files/lower_nosep_data.csv",index=False)
- Preparing data The texts are still strings while machine doesn’t recognize. For machine, each word is represented by an id. What’s more, we usually use mini-batch for training in practice, allowing the process running in parallel. With the help of Dataset and pre-trained tokenizer, it’s not hard to achieve those goals.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
from datasets import Dataset
from transformers import RobertaTokenizer
from torch.utils.data import DataLoader
Tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
class CustomDataset(Dataset):
def __init__(self, Data, tokenizer, max_len):
self.tokenizer = tokenizer
self.allinfo = Data
self.text = self.allinfo['text']
self.labels = self.allinfo["label"]
self.max_len = max_len
def __len__(self):
return len(self.text)
def __getitem__(self, index):
inputs = self.tokenizer.encode_plus(
self.text[index],
None,
add_special_tokens=True,
max_length=self.max_len,
padding='max_length',
return_token_type_ids=True,
truncation=True
)
ids = inputs['input_ids']
mask = inputs['attention_mask']
token_type_ids = inputs["token_type_ids"]
return {'ids': torch.tensor(ids, dtype=torch.long),'mask': torch.tensor(mask, dtype=torch.long),
'token_type_ids': torch.tensor(token_type_ids, dtype=torch.long),
'targets': torch.tensor(self.labels[index], dtype=torch.float)}
Here CustomDataset inherit from its parent class–Dataset. We, however, need to rewrite some methods. There is one thing worth to mention: in encode_plus(), parameter add_special_tokens=True, meaning every time at the beginning of a sentence, there will be a special token [CLS] and at the end [SEP]; padding=True means those texts whose tokens are less than max tokens will be filled with special tokens. Thereby sentence length is always the same. truncation=True is to make sure the sentence length won’t beyond the limitation.
There might be one more confusing thing about the code–What is mask? Mask is to prevent the model from seeing the true id and let it guess what’s the true word. This is implemented in pre-training round of BERT.
Building model
First block is BERT, and feed the model with input id list.
And then pass the sentence embedding into a feed-forward network and predict corresponding labels.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class BERTClass(torch.nn.Module):
def __init__(self):
super(BERTClass, self).__init__()
self.l1 = transformers.DistilBertModel.from_pretrained('distilbert-base-uncased', output_hidden_states=False)
self.l2 = torch.nn.Sequential(
torch.nn.Linear(768, 768),
torch.nn.ReLU(),
torch.nn.Dropout(0.1),
torch.nn.Linear(768, 126),
)
def forward(self, ids, mask):
output_1 = self.l1(ids, attention_mask=mask)
output = self.l2(output_1[0])
output = output[:, 0, :].squeeze()
return output
model = BERTClass().to(device)
def loss_fn(outputs, targets):
return torch.nn.BCEWithLogitsLoss()(outputs, targets)
Training
Then we apply the model in training. The step consists of getting batch data, training & saving the model and finally evaluating the accuracy.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def train(epoch):
model.train()
fin_targets = []
fin_outputs = []
total_loss = 0
for _, data in enumerate(Data_loading.train_loader, 0):
ids = data['ids'].to(device, dtype=torch.long)
mask = data['mask'].to(device, dtype=torch.long)
# print(torch.max(ids),torch.min(ids))
# print(torch.max(mask),torch.min(mask))
# token_type_ids = data['token_type_ids'].to(device, dtype = torch.long)
targets = data['targets'].to(device, dtype=torch.float)
outputs = model(ids, mask)
optimizer.zero_grad()
loss = loss_fn(outputs, targets)
total_loss += loss.item()
fin_targets.extend(targets.cpu().detach().numpy().tolist())
fin_outputs.extend(torch.sigmoid(outputs).cpu().detach().numpy().tolist())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if _ % 500 == 0 and _ != 0:
print('Epoch: {}, batch:{}, Avg Loss: {}'.format(epoch+1, _, total_loss/(_+1)), flush=True)
checkpoint = {
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict()}
return fin_targets, fin_outputs, total_loss/len(Data_loading.train_loader), checkpoint
The training process takes quite a long time. For RoBERTa model, about 20+ hours is spent. As expected, the distilled model has a faster training step, with about 12 hours.
The validation step basically remains the same but doesn’t save models.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#!/bin/bash
#SBATCH -n 1 # node you request
#SBATCH -p gpu # use gpu
#SBATCH -t 20:00:00 # time for gpu
#SBATCH --mem= Memory size (GB)
#SBATCH --gres=gpu:v100:1
#SBATCH -J name of the project
#SBATCH -o <outcome file path>
#SBATCH -e <error file path>
#SBATCH --account= <your project id>
#SBATCH --mail-type=ALL
#SBATCH --mail-user= <your email address>
module purge
module load pytorch
python train.py
At the university, I use Puhti to enable GPU training and above show some bash commands and configurations.
Evaluation
The following plot is the performance of distlBERT. 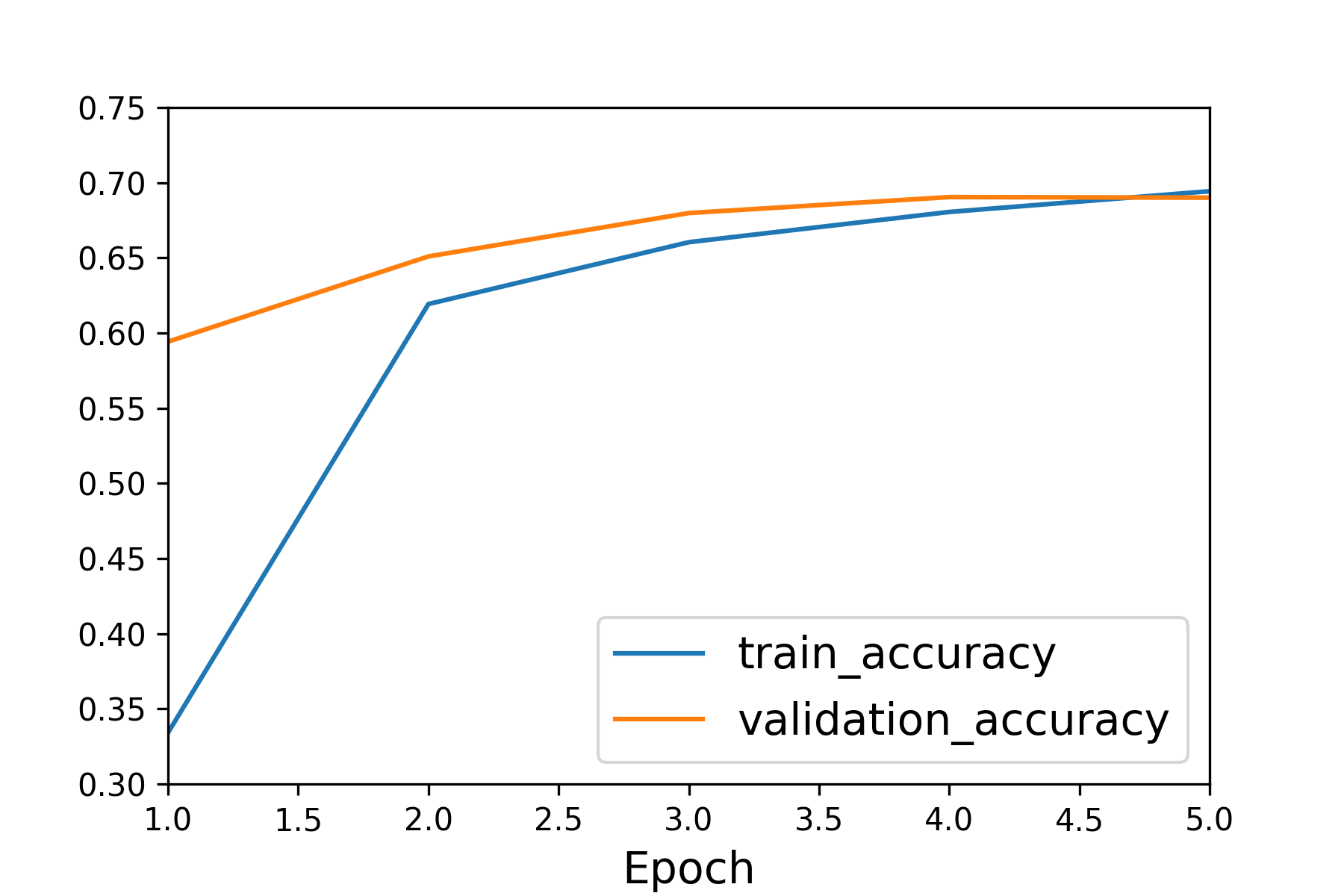 After several epochs, the model reaches about 70% in accuracy.
After several epochs, the model reaches about 70% in accuracy.
Here the way of calculating accuracy is somewhat different from usual one. The model could miss one true topic or predict a wrong topic. The accuracy computation is achieved via sklearn.metrics.accuracy_score.
Only if the predicted labels match exactly the true values, will it be counted as a correct prediction. There are quite a few types of topics, so each topic receives an accuracy value. The final one is the averaged value. In fact, I also applied f1 score (both micro and macro).
The results show that RoBERTa performs better than DistlBERT. Although, the compressed model falls behind 1~2% in accuracy, it indeed saves more time.
Project review
Overall in this project, I go through the pipeline of solving a NLP problem.
I familiarized with the necessary steps of text classification. Also, I had hands-on experience of using BERT model.
There are actually more things can be done to improve the results. For example, text cleaning or how to deal with the imbalanced labels. Efforts of data augmentation should be made as well.
Some codes are adopted from the internet. The followings are some sites I referred while doing the project.
BERT, RoBERTa, DistilBERT, XLNet — which one to use?
Transformers for Multi-Label Classification made simple
Multi-label Text Classification with BERT using Pytorch